Security in modern software development
Antti Vähä-Sipilä, F-Secure
antti.vaha-sipila@f-secure.com / avs@iki.fi
Twitter: @anttivs
Available online at https://www.fokkusu.fi/security-in-ci-slides/
Hey! This is old stuff, written originally in 2013 .. 2014. Pre-DevSecOps!
Various versions and parts of this presentation have been presented (at least) at Topconf Tallinn 2012, the BSIMM Community Conference 2013, SAP Security Expert Summit 2014, and Korkeakoulujen valtakunnalliset IT-päivät 2014. Parts of the material have been produced under the Digile Cloud Software Program.
You are standing in the basement. There is an arrow pointing up. You hear the muffled noise of the audience upstairs. There is a sign here that reads:
Congratulations! You found the explanations track. Each slide has a 'down' arrow, and pressing it will show some more detail of what I will be talking about. This is intended for those who are reading the slides outside the live presentation. Press the 'up' arrow to get back on the main slides track.
Outline
- Making security work visible
- Automating security work
- Hazards on the road
A "modern" process?
- Work on a prioritised backlog
- Including security tasks
- Incremental development
- No "End of Level Boss" security assessment
- Test automation (& QA in dev team)
- Basic security scans done automatically...
- Continuous Integration
- ...all the time
- Automated deployment
- Deployment configuration under source control
As a background, I am assuming a "modern" software development lifecycle.
The hallmarks of "modern" development are, in my opinion, that the work is coordinated through a prioritised backlog that can change at any time as a result of changing business climate ("agile"); that development is incremental (code a bit, write tests, code a bit more); that there is no separate quality assurance function but QA is done by the development team primarily through implementing automated test cases; builds are run off a version control system in a continuous fashion; and deployment to production is automated to the maximum degree.
Things that are not modern are dev / test / ops handovers, non-prioritised requirements lists, over-reliance on manual testing, and testing and operations in "golden" or "administered" environments.
Security-wise, these principles mean that security activities are conducted all the time, not just at the end of the development or at a go-live point; that all "easy" security tests, such as fuzzing and vulnerability scanning are automated to the maximum extent; and that host and deployment configurations are under source code control, and thus subject to code review and automated security checks.
Making security work visible
Driving it through the backlog
- Know what needs doing
- Threat modelling
- Privacy impact assessment
- Put the work on the backlog
- Attacker (misuse) stories
- Security features (functional controls)
- Acceptance criteria
The prioritised (product) backlog is supposed to contain all the work that the development team has in front of it. In reality, though, non-functional considerations are often missing, and are either implicit or documented in team-specific "Definitions of Done".
Software security work needs to be made visible, and it needs to be prioritised against (functional) business needs. This is because investment in security work is a business decision, and investment in security compete with other investments.
In many cases, the best way to find out what to put on your product backlog is through threat modelling, and in the privacy domain, a PIA (privacy impact assessment). How to do this is beyond this presentation, but you should look at my other presentation on privacy requirements. You should schedule the treat modelling/PIA activity through the backlog as well.
The stuff you come up with can be new design requirements, new security controls, required use of a privacy-enhancing technology (PET), new test needs, guidelines to follow, and so on. How to put these on the backlog will be discussed soon.
Non-optimal:
- "Themed" sprints (e.g., hardening sprints)
- "Bucketized" security development work
- Teams' Definition of Done
There have been other suggestions of how security work ought to be driven. I, myself, have advocated using the Definition of Done too, but I’ve changed my mind.
Themed sprints cause work to be "pushed into the future", i.e., causes technical debt to accrue until a themed sprint. It is not guaranteed that the themed sprint will ever come, or that debt can be paid back during the allocated time. "Bucketization" of security development work is an idea where some security engineering things most be done at every increment, some at every second, etc.; this is bad as it decouples security work from the actual functional requirements and takes the control away from product management. From outside the team, it also looks like the team just gets slower in their throughput (shows decreased velocity). Having work in a Definition of Done is just another way at looking at bucketization. Instead of a Definition of Done, use Acceptance Criteria that are tagged to specific functional requirements. When you toss out a functional requirement, the Acceptance Criteria - and the related security work - also goes out.
Work that is outside the backlog is problematic because it doesn't get prioritised against all other backlog items. This puts it in a category that is not subject to the same business decisions - either it becomes "sacred" work that cannot be touched, or work that doesn't get done at all.
Also, this is a kind of "invisible work" or "dark matter" - for an external observer, it looks like the team wastes their time doing something else than the features on the backlog. The external observer doesn't see that the team is busy fuzzing or conducting ARA or whatever. In the worst case, they'll start to pressure the team to drop this invisible work and just get on with the features.
(A side comment: A Definition of Done is a set of quality criteria that describes when a Backlog item is ready for delivery. Most agile coaches agree that a Definition of Done should be agreed between the Product Owner and the development team; and in many organisations, the Definition of Done is imposed as an external requirement set on the team. In the former case, is not guaranteed to contain software security activities and in the latter case, it is not guaranteed that the teams follow it.)
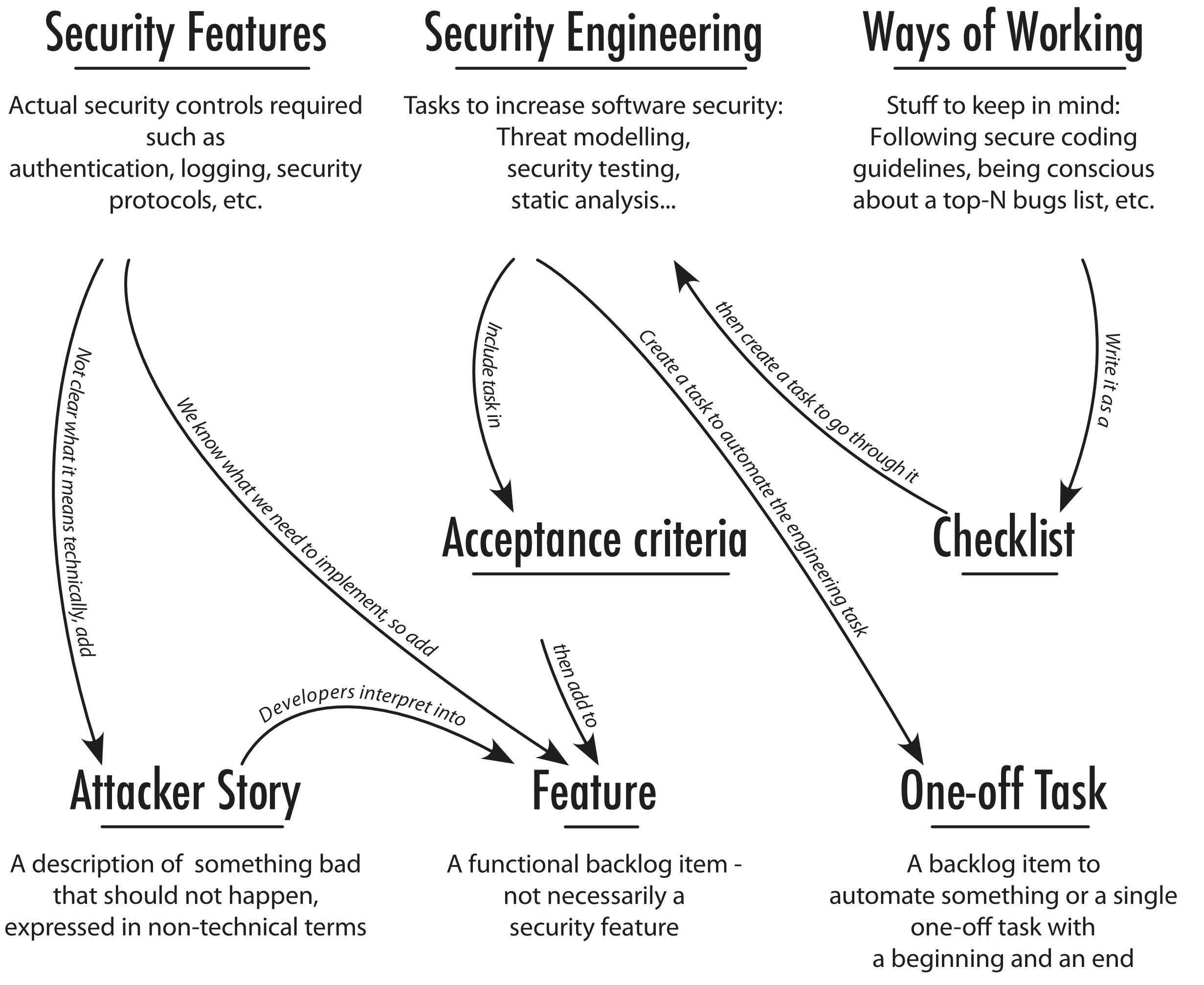
This picture can also be found in my article on Security In Agile Product Management, in Handbook of Secure Agile Software Lifecycle, Cloud Software Finland, 2014. The small text on the arrows explains what is happening. To summarise:
- If you have a (functional) security feature, just put it on the backlog as a feature.
- If you have a security engineering task - something that has a beginning and an end (like a threat modelling session or a web security scan run):
- Is it recurring? If it can be automated, create a one-off task to automate it, and put that task on the backlog. Automation will take care of the task from there on. [Assuming you have test automation!]
- If it is not recurring, or cannot be automated, write it as an acceptance criterion and tag that with an existing backlog item. (Acceptance criteria are kind of mini-Definitions of Done, like specific quality criteria that need to be fulfilled for this feature to be deemed complete. But unlike Definition of Done, Acceptance Criteria are defined and live as a part of the Backlog item.)
- If you have a way of working, which is not a task with a beginning and an end, create a guideline or a checklist and treat that according to 2), above.
Why better?
- All security work is visible and gets prioritised against other business needs.
- Security work that has not yet been done is explicitly visible.
- Security work has been done is in the "done" pile, showing as evidence of work done.
- Feature-specific security work follows the feature. Drop the feature, drop security work.
Caveats:
- If your organisation uses acceptance testing that has been segregated from your development (i.e., different people develop and test), it is hard to drive testing through the backlog.
- What to do to underlying architectural decisions that pre-date the actual implementation, like selecting a platform or implementation language? I don't have a really good answer, but it would fit the concept of a "Sprint Zero" - a kind of bootstrapping sprint many teams use. But that would be a themed sprint which I already denounced earlier. So I need to think more about this. For now, I suggest doing a "Sprint Zero" and considering applying attack modeling activities (BSIMM activity AM2.2) in that context.
- Also, high level "enterprise security architecture" work that has been built for BDUF is something is tricky. If the organisation has a separate enterprise architecture ivory^H^H^H^H^H team who does this sort of work outside the dev teams before actual development starts, it really isn't very Agile, and I don't have a good answer for that.
Automating security work
Recap: Automating tests
- Turn policies and ways of working into technical checklists
- Require adherence to a checklist in acceptance criteria
- Implement the checklist as automated tests
- Acceptance = automated tests pass
- No tests / not passing = Not done
"Easy" to automate?
- Static analysis (at least linters)
- Scan dependencies for known vulns
- Extract software inventory, track vuln data
- Web app automated vuln scanning
- Cookie compliance scans
- Database injection testing
- Fuzzing
- TLS configuration on deployed servers
- Open ports, running processes on deployed hosts
If you talk to static analysis tool vendors, they're likely to portray the tool as a silver bullet. In test automation and especially Continuous Delivery, you'll want to ensure that the analysis provides rapid results. The closer you bring it to the actual coding, the better the feedback loop is likely to be. Some would like IDE or editor integration, and if that is available for your platform / framework combination, why not? When evaluating a static analysis tool, you should ensure you pilot it with your code and your set of frameworks. If you change your language and frameworks often from project to project, it may be that static analysis is not your first choice as a software security control.
Knowing your software inventory is very useful for vulnerability tracking and management, and the build process gives you a real opportunity to see exactly what you're including. As an example, Node.js applications' dependencies (and their dependencies) can be checked against known vulnerabilities with nsp. Running this sort of tools at build time (or test run time) makes sense.
If you deploy servers to a cloud, running sanity checks against them from inside and outside of those nodes is a good idea, because that helps to catch issues related to changed deployment templates. Having your host configuration and deployment automation under source control is a good idea.
Hard to automate
- Threat modelling
- Privacy impact assessments
- Exploratory security testing
In other words, finding security bugs is doable in test automation. Finding security flaws requires manual work to be scheduled.
Demo: Mittn
- A security test framework built with Python / Behave
- Describe tests in Gherkin (a BDD language)
- Minimise cost of adding tests for new functionality
- Once in use, adding tests requires no security expertise
It's work in progress, but open sourced at
https://github.com/F-Secure/mittn
Technically speaking, Mittn is a step library for Behave that provides "glue" to run several different security test tools. The heavy lifting is done by Behave (the test runner) and the third party test tools. Mittn just tries to make it all usable in a Continuous Integration context.
The main selling point of Mittn is that once set up, the developers should not need to know the intricacies of setting up the test tools. Additional test cases to cover new additional functionality can be added by simply adding more test cases written in Gherkin.
Current Mittn features
- Check the TLS config of a deployed server (with sslyze)
- Run an automated web app scan (with Burp Suite Professional)
- Reuse existing functional tests (e.g., Selenium)
- Inject static and fuzzed inputs to web forms and JSON APIs (with Radamsa)
- Reuse existing API specs and functional test cases
Burp Suite scans
Background: Test that the database and Burp Suite are configured correctly
Given an sqlite baseline database
And a working Burp Suite installation
@slow
Scenario:
Given scenario id "1"
And all URIs successfully scanned
When scenario test is run through Burp Suite with "10" minute timeout
Then baseline is unchanged
This is an example of a Gherkin file that runs a Burp Suite Professional scan. The "Background" block sets up a database (in this case, a sqlite database, but Postgres is fine and I plan to refactor for DB abstraction) that receives all the findings and acts as a repository for false positives. The "Scenario" block instructs the framework to run a test scenario number 1, which can be, for example, a specific functional test implemented in Selenium.
In this mode of operation, this is not very BDD.
JSON API fuzzing
Scenario:
Given scenario id "1"
And an authentication flow id "1"
And valid case instrumentation with success defined as "100-499"
And target URL "http://mittn.org/dev/null"
And valid JSON submissions using "POST" method
| submission |
| {"foo": 1, "bar": "OMalleys"} |
| {"foo": 2, "bar": "Liberty or Death"} |
| {"foo": 42, "bar": "Kauppuri 5"} |
And tests conducted with HTTP methods "POST,PUT,DELETE"
And a timeout of "5" seconds
When fuzzing with "100" fuzz cases for each key and value
And storing any new cases of return codes "500,502-599"
And storing any new cases of responses timing out
And storing any new invalid server responses
And storing any new cases of response bodies that contain strings
| server error |
| exception |
| invalid response |
| fatal error |
Then no new issues were stored
This is an example of a run where the tool is used to run fuzz testing against a JSON API. The Gherkin file contains a number of valid sample submissions, and that data is used to feed the fuzzer. Various simple heuristics are used to detect server-side failures. The "authentication flow identifier" defines which authentication / authorisation is required; for example, if you need oAuth, you can implement a login using it and the framework will re-authorise every time the test system gets an "unauthorised" response.
Here, the benefit of using Gherkin is better visible. New APIs can be added into tests just by listing some valid cases of JSON submissions. The actual security test setup does not need to be touched.
In addition to fuzzing, the tool also has a ready-made injection library that aims to discover various other injection vulnerabilities - including database injections, PHP specific injections, shell injections, and so on. Fuzzing is likely to be most interesting when the server uses components or libraries written in C/C++, and passes some of the data to those components.
Other similar approaches
- Gauntlt (Ruby)
- BDD-Security (Java; the most pure "BDD" test system of these)
The three tools (Mittn, Gauntlt and BDD-Security) were featured in an Adobe blog post in July 2014.
Hazards
Your problems are likely not technical
- Bad or non-existent requirements
- Up-front investment in test automation not done
- A security assessment ("audit") mindset
- No functional test coverage to leverage
- Initially a lot of false positives from tools
Avoiding problems
- Coach your product management
- Join forces with your QA automation advocates
- Bring up automated security test needs in threat modelling
- Absorb the false positive hit yourself at first
Q&A
Feedback welcome:
@anttivs
antti.vaha-sipila@f-secure.com
avs@iki.fi

Powered by reveal.js